嘉定區智能驗證模型要求
防止過擬合:通過對比訓練集和驗證集上的性能,可以識別模型是否存在過擬合現象(即模型在訓練數據上表現過好,但在新數據上表現不佳)。參數調優:驗證集還為模型參數的選擇提供了依據,幫助找到比較好的模型配置,以達到比較好的預測效果。增強可信度:經過嚴格驗證的模型在部署后更能贏得用戶的信任,特別是在醫療、金融等高風險領域。二、驗證模型的常用方法交叉驗證:K折交叉驗證:將數據集隨機分成K個子集,每次用K-1個子集作為訓練集,剩余的一個子集作為驗證集,重復K次,每次選擇不同的子集作為驗證集,**終評估結果為K次驗證的平均值。交叉驗證:如果數據量較小,可以采用交叉驗證(如K折交叉驗證)來更評估模型性能。嘉定區智能驗證模型要求
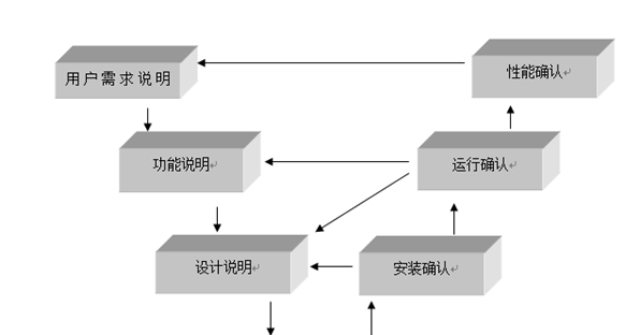
指標數目一般要求因子的指標數目至少為3個。在探索性研究或者設計問卷的初期,因子指標的數目可以適當多一些,預試結果可以根據需要刪除不好的指標。當少于3個或者只有1個(因子本身是顯變量的時候,如收入)的時候,有專門的處理辦法。數據類型絕大部分結構方程模型是基于定距、定比、定序數據計算的。但是軟件(如Mplus)可以處理定類數據。數據要求要有足夠的變異量,相關系數才能顯而易見。如樣本中的數學成績非常接近(如都是95分左右),則數學成績差異大部分是測量誤差引起的,則數學成績與其它變量之間的相關就不***。嘉定區智能驗證模型要求這樣可以多次評估模型性能,減少偶然性。
驗證模型是機器學習過程中的一個關鍵步驟,旨在評估模型的性能,確保其在實際應用中的準確性和可靠性。驗證模型通常包括以下幾個步驟:數據準備:數據集劃分:將數據集劃分為訓練集、驗證集和測試集。訓練集用于訓練模型,驗證集用于調整模型參數(如超參數調優),測試集用于**終評估模型性能。數據預處理:包括數據清洗、特征選擇、特征縮放等,確保數據質量。模型訓練使用訓練數據集對模型進行訓練,得到初始模型。根據需要調整模型的參數和結構,以提高模型在訓練集上的性能。
模型驗證是機器學習和統計建模中的一個重要步驟,旨在評估模型的性能和可靠性。通過模型驗證,可以確保模型在未見數據上的泛化能力。以下是一些常見的模型驗證方法和步驟:數據劃分:訓練集:用于訓練模型。驗證集:用于調整模型參數和選擇模型。測試集:用于**終評估模型性能,確保模型的泛化能力。交叉驗證:k折交叉驗證:將數據集分成k個子集,輪流使用每個子集作為驗證集,其余作為訓練集。**終結果是k次驗證的平均性能。留一交叉驗證:每次只留一個樣本作為驗證集,其余樣本作為訓練集,適用于小數據集。使用網格搜索(Grid Search)或隨機搜索(Random Search)等方法對模型的超參數進行調優,以找到參數組合。

構建模型:在訓練集上構建模型,并進行必要的調優和參數調整。驗證模型:在驗證集上評估模型的性能,并根據評估結果對模型進行調整和優化。測試模型:在測試集上測試模型的性能,以驗證模型的穩定性和可靠性。解釋結果:對驗證和測試的結果進行解釋和分析,評估模型的優缺點和改進方向。四、模型驗證的注意事項在進行模型驗證時,需要注意以下幾點:避免數據泄露:確保驗證集和測試集與訓練集完全**,避免數據泄露導致驗證結果不準確。根據需要調整模型的參數和結構,以提高模型在訓練集上的性能。嘉定區智能驗證模型要求
驗證模型是機器學習和統計建模中的一個重要步驟,旨在評估模型的性能和泛化能力。嘉定區智能驗證模型要求
性能指標:分類問題:準確率、精確率、召回率、F1-score、ROC曲線、AUC等。回歸問題:均方誤差(MSE)、均方根誤差(RMSE)、平均***誤差(MAE)等。模型復雜度:通過學習曲線分析模型的訓練和驗證性能,判斷模型是否過擬合或欠擬合。超參數調優:使用網格搜索(Grid Search)或隨機搜索(Random Search)等方法優化模型的超參數。模型解釋性:評估模型的可解釋性,確保模型的決策過程可以被理解。如果可能,使用**的數據集進行驗證,以評估模型在不同數據分布下的表現。通過以上步驟,可以有效地驗證模型的性能,確保其在實際應用中的可靠性和有效性。嘉定區智能驗證模型要求
上海優服優科模型科技有限公司在同行業領域中,一直處在一個不斷銳意進取,不斷制造創新的市場高度,多年以來致力于發展富有創新價值理念的產品標準,在上海市等地區的商務服務中始終保持良好的商業口碑,成績讓我們喜悅,但不會讓我們止步,殘酷的市場磨煉了我們堅強不屈的意志,和諧溫馨的工作環境,富有營養的公司土壤滋養著我們不斷開拓創新,勇于進取的無限潛力,上海優服優科模型科技供應攜手大家一起走向共同輝煌的未來,回首過去,我們不會因為取得了一點點成績而沾沾自喜,相反的是面對競爭越來越激烈的市場氛圍,我們更要明確自己的不足,做好迎接新挑戰的準備,要不畏困難,激流勇進,以一個更嶄新的精神面貌迎接大家,共同走向輝煌回來!
- 金山區優良汽車設計開發優勢 2025-07-07
- 上海自動驗證模型便捷 2025-07-07
- 虹口區口碑好驗證模型熱線 2025-07-07
- 楊浦區口碑好工程樣車試制要求 2025-07-07
- 黃浦區口碑好驗證模型咨詢熱線 2025-07-07
- 虹口區正規展示車加工熱線 2025-07-07
- 黃浦區正規驗證模型大概是 2025-07-07
- 長寧區正規驗證模型訂制價格 2025-07-07
- 普陀區銷售驗證模型咨詢熱線 2025-07-07
- 楊浦區銷售展示車加工咨詢熱線 2025-07-07
- 重慶禮盒包裝設計生意增長 2025-07-07
- 吳中區上門高新企業認證售后服務 2025-07-07
- 上海士工膜焊接質量檢測報價 2025-07-07
- 廈門無損檢測報價 2025-07-07
- 拓客禮品費用標準 2025-07-07
- 潮州一站式潮汕旅游攻略平均價格 2025-07-07
- 離心泵巴西NR13認證多少錢 2025-07-07
- 法國PCT專利申請需要哪些材料 2025-07-07
- 四川實習生工作靠譜的公司 2025-07-07
- 黃浦區本地整車運輸平臺 2025-07-07